
Why for-range behaves differently depending on the size of the element (A peek into go compiler optimization)
It’s all started when my colleague asked this question.
1package main
2
3import "testing"
4
5const size = 1000000
6
7type SomeStruct struct {
8 ID0 int64
9 ID1 int64
10 ID2 int64
11 ID3 int64
12 ID4 int64
13 ID5 int64
14 ID6 int64
15 ID7 int64
16 ID8 int64
17}
18
19func BenchmarkForVar(b *testing.B) {
20 slice := make([]SomeStruct, size)
21 b.ReportAllocs()
22 b.ResetTimer()
23 for i := 0; i < b.N; i++ {
24 for _, s := range slice { // index and value
25 _ = s
26 }
27 }
28}
29func BenchmarkForCounter(b *testing.B) {
30 slice := make([]SomeStruct, size)
31 b.ReportAllocs()
32 b.ResetTimer()
33 for i := 0; i < b.N; i++ {
34 for i := range slice { // only use the index
35 s := slice[i]
36 _ = s
37 }
38 }
39}
Which one do you think is faster?
1$ go test -bench .
2goos: linux
3goarch: amd64
4BenchmarkForVar-4 4363 269711 ns/op 0 B/op 0 allocs/op
5BenchmarkForCounter-4 4195 285952 ns/op 0 B/op 0 allocs/op
6PASS
7ok _/test1 2.685s
It’s pretty much the same. However, if we increase the size of the struct by adding another field ID9 int64
The result becomes significantly different.
1$ go test -bench .
2goos: linux
3goarch: amd64
4BenchmarkForVar-4 282 4264872 ns/op 0 B/op 0 allocs/op
5BenchmarkForCounter-4 4363 269761 ns/op 0 B/op 0 allocs/op
6PASS
7ok _/test1 3.255s
This problem become intriguing, so I dig a little deeper. I would like to point out that the code is a contrived example. It would probably not applied in a production code. I am **not** going to focus on the benchmark or which for-range works better but rather exploring how Go compiles and demonstrating useful Go tools in the process.
The code below also contains some assembly code. I am not going into too much detail, so I would not worry if you are not familiar with it. My intention is to show how the generated code differs and what could be the reason for it.
I am going to focus on for _, s = range slice loop (ForVar). To make it simpler I create a main.go and struct.go
main.go
1package main
2
3func main() {
4 const size = 1000000
5
6 slice := make([]SomeStruct, size)
7 for _, s := range slice {
8 _ = s
9 }
10}
I’ll skip the struct.go here since it’s pretty trivial.
Generating Assembly Code
To look into what instructions are generated, we can use go tool compile -S. This will print out the generated
assembly code to stdout. I also Skipped some lines that are not directly related to our code.
according to asm package doc
The FUNCDATA and PCDATA directives contain information for use by the garbage collector; they are introduced by the compiler.
1$ go tool compile -S main.go type.go | grep -v FUNCDATA | grep -v PCDATA
Here are the generated assembly code for both version.
version with 9 int64
This struct contains 9 int64 and has the size 72 bytes
1"".main STEXT size=93 args=0x0 locals=0x28
2 ...
3 0x0024 00036 (main_var.go:6) MOVQ AX, (SP)
4 0x0028 00040 (main_var.go:6) MOVQ $1000000, 8(SP)
5 0x0031 00049 (main_var.go:6) MOVQ $1000000, 16(SP)
6 0x003a 00058 (main_var.go:6) CALL runtime.makeslice(SB)
7 0x003f 00063 (main_var.go:6) XORL AX, AX # set AX = 0
8 0x0041 00065 (main_var.go:7) INCQ AX # AX++
9 0x0044 00068 (main_var.go:7) CMPQ AX, $1000000 # AX < 1000000
10 0x004a 00074 (main_var.go:7) JLT 65 # JUMP to 00065 (next iteration)
11 ...
Here you can see that at line 00065, the loop does nothing except increasing the counter. Let’s compare it with the
larger struct.
**version with 10 int64**
The struct now contains 10 int64 and has the size 80 bytes
10x0000 00000 (main_var.go:3) TEXT "".main(SB), ABIInternal, $120-0
2 ...
3 0x0044 00068 (main_var.go:6) XORL CX, CX # CX = 0
4 0x0046 00070 (main_var.go:7) JMP 76
5 0x0048 00072 (main_var.go:7) ADDQ $80, AX
6 0x004c 00076 (main_var.go:7) PCDATA $0, $2 # setup temporary variable autotmp_7
7 0x004c 00076 (main_var.go:7) LEAQ ""..autotmp_7+32(SP), DI
8 0x0051 00081 (main_var.go:7) PCDATA $0, $3
9 0x0051 00081 (main_var.go:7) MOVQ AX, SI
10 0x0054 00084 (main_var.go:7) PCDATA $0, $1
11 0x0054 00084 (main_var.go:7) DUFFCOPY $826 # copy content of the struct
12 0x0067 00103 (main_var.go:7) INCQ CX # CX++
13 0x006a 00106 (main_var.go:7) CMPQ CX, $1000000 # CX < 1000000
14 0x0071 00113 (main_var.go:7) JLT 72 # JUMP to 0072 (next iteration)
15 ...
The conclusion is that with 80 bytes struct, every iteration copies the value of the element.
SSA Optimization
To understand how this code is generated, we first need to understand how GO compile a source code.
Stream wrote a very good introduction to the topic on
How a Go Program Compiles down to Machine Code.
The short version is the compiler does:
- break up the source code content into tokens (Scanning)
- Construct Abstract Syntax Tree using the tokens (Parsing)
- Generate Intermediate Representation (IR) with Static Single Assignment (SSA) form
- Iteratively optimize the IR with multiple pass
Fortunately GO provides amazing tool that helps us getting more insight into the optimization process. We can generate the SSA output for each stage of transformation with:
1$ GOSSAFUNC=main go tool compile -S main_var.go type_small.go
The command will generate `ssa.html` in the same folder.
Each column represents the optimization pass, and the result of the IR code. When we click on a block, variable, or line. It will colorize the associated element, so we can track changes easily.
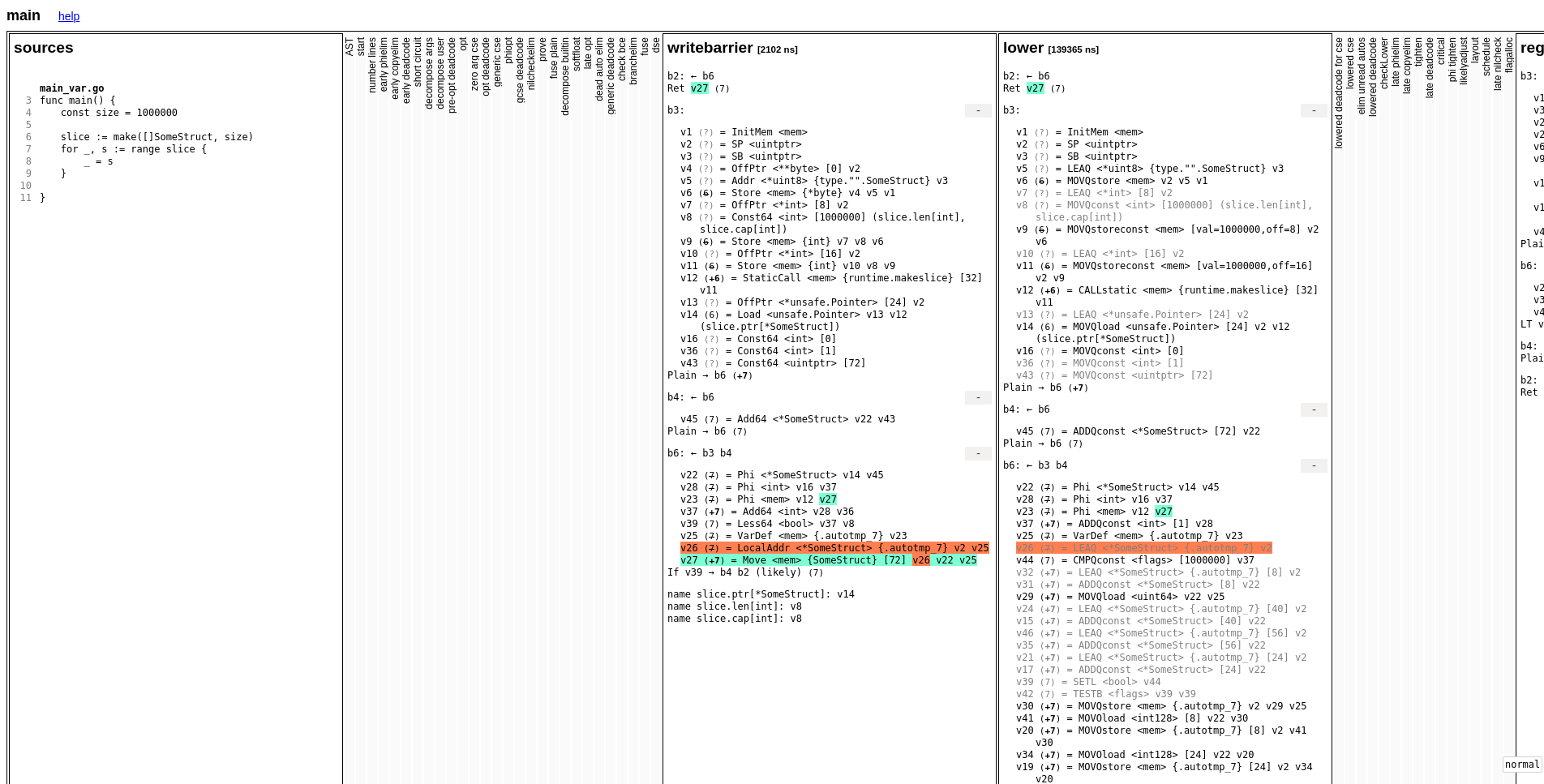](forVar_small_ssa.png){kind=link}
After comparing each step, I found out that the generated code was identical until the writebarrier pass.
let’s focus on block b6
writebarrier (identical on both versions)
1b6: ← b3 b4
2 v22 (7) = Phi <*SomeStruct> v14 v45
3 v28 (7) = Phi <int> v16 v37
4 v23 (7) = Phi <mem> v12 v27
5 v37 (+7) = Add64 <int> v28 v36
6 v39 (7) = Less64 <bool> v37 v8
7 v25 (7) = VarDef <mem> {.autotmp_7} v23
8 v26 (7) = LocalAddr <*SomeStruct> {.autotmp_7} v2 v25
9 v27 (+7) = Move <mem> {SomeStruct} [72] v26 v22 v25
If you see on v26 & v27, it does Move (or Copy) the content of the struct to local variable autotmp_7.
The lower pass basically convert the IR code into specific architecture low level code. Let’s have a look at the generated output.
Don’t be afraid if you don’t really understand the assembly. What I wanted to show is the different code that was generated during
the lower pass.
lower with 9 int64
1b6: ← b3 b4
2
3 v22 (7) = Phi <*SomeStruct> v14 v45
4 v28 (7) = Phi <int> v16 v37
5 v23 (7) = Phi <mem> v12 v27
6 v37 (+7) = ADDQconst <int> [1] v28
7 v25 (7) = VarDef <mem> {.autotmp_7} v23
8 v26 (7) = LEAQ <*SomeStruct> {.autotmp_7} v2
9 v44 (7) = CMPQconst <flags> [1000000] v37
10 v32 (+7) = LEAQ <*SomeStruct> {.autotmp_7} [8] v2
11 v31 (+7) = ADDQconst <*SomeStruct> [8] v22
12 v29 (+7) = MOVQload <uint64> v22 v25
13 v24 (+7) = LEAQ <*SomeStruct> {.autotmp_7} [40] v2
14 v15 (+7) = ADDQconst <*SomeStruct> [40] v22
15 v46 (+7) = LEAQ <*SomeStruct> {.autotmp_7} [56] v2
16 v35 (+7) = ADDQconst <*SomeStruct> [56] v22
17 v21 (+7) = LEAQ <*SomeStruct> {.autotmp_7} [24] v2
18 v17 (+7) = ADDQconst <*SomeStruct> [24] v22
19 v39 (7) = SETL <bool> v44
20 v42 (7) = TESTB <flags> v39 v39
21 v30 (+7) = MOVQstore <mem> {.autotmp_7} v2 v29 v25 # <-- start translated Move instruction
22 v41 (+7) = MOVOload <int128> [8] v22 v30
23 v20 (+7) = MOVOstore <mem> {.autotmp_7} [8] v2 v41 v30
24 v34 (+7) = MOVOload <int128> [24] v22 v20
25 v19 (+7) = MOVOstore <mem> {.autotmp_7} [24] v2 v34 v20
26 v33 (+7) = MOVOload <int128> [40] v22 v19
27 v38 (+7) = MOVOstore <mem> {.autotmp_7} [40] v2 v33 v19
28 v47 (+7) = MOVOload <int128> [56] v22 v38
29 v27 (+7) = MOVOstore <mem> {.autotmp_7} [56] v2 v47 v38
**`lower` with 10 int64**
1b6: ← b3 b4
2
3 v22 (7) = Phi <*SomeStruct> v14 v45
4 v28 (7) = Phi <int> v16 v37
5 v23 (7) = Phi <mem> v12 v27
6 v37 (+7) = ADDQconst <int> [1] v28
7 v25 (7) = VarDef <mem> {.autotmp_7} v23
8 v26 (7) = LEAQ <*SomeStruct> {.autotmp_7} v2
9 v44 (7) = CMPQconst <flags> [1000000] v37
10 v32 (+7) = LEAQ <*SomeStruct> {.autotmp_7} [8] v2
11 v31 (+7) = ADDQconst <*SomeStruct> [8] v22
12 v29 (+7) = MOVQload <uint64> v22 v25
13 v39 (7) = SETL <bool> v44
14 v42 (7) = TESTB <flags> v39 v39
15 v30 (+7) = MOVQstore <mem> {.autotmp_7} v2 v29 v25 # <-- start translated Move instruction
16 v27 (+7) = DUFFCOPY <mem> [826] v32 v31 v30
17
18LT v44 → b4 b2 (likely) (7)
The later version uses DUFFCOPY to perform the Move operation. This logic I believe is due to a rewrite rule
rewriteAMD64.go. It’s an optimization
to Move a large byte on memory.
1// match: (Move [s] dst src mem)
2// cond: s > 64 && s <= 16*64 && s%16 == 0 && !config.noDuffDevice
3// result: (DUFFCOPY [14*(64-s/16)] dst src mem)
At a later SSA pass (elim unread autos) the compiler can detect that there are unused temporary
variable for the first version (9 int64 struct). Thus, the Move instruction can be removed.
This is not the case with for the `DUFFCOPY’ version.
That’s why the generated machine code is less optimized than the previous.
Note: A Duff Device is a loop optimization by splitting the task and reduce the number of loop.
Conclusion
for-range behaves differently depending on the struct size is due to Compiler SSA optimization. The compiler generated
a different machine code for the larger struct where at a later pass it did not detect unused variable. The opposite happen
for the smaller struct. At a later pass, it detected that some variables are un used. It removes the copy of element
instruction on each iteration.